Automated Luck: How My Twitter Bot Won Contests While I Slept
Winning Twitter contests through code - building a bot to win prizes, mastering APIs, and learning Python. Here's what I gained from a year of algorithmic luck.

The Inspiration
A few years ago, I stumbled upon Hunter Scott’s fascinating DEF CON 24 talk titled “RT to Win: 50 Lines of Python Made Me the Luckiest Guy on Twitter”. The concept was brilliantly simple yet remarkably effective: create a bot that automatically finds and enters Twitter giveaways.
Scott’s experiment ran for about 9 months, entered approximately 165,000 contests, and won nearly 1,000 prizes. His haul included everything from concert tickets to a trip to New York Fashion Week, and even unusual items like a cowboy hat signed by the cast of a Mexican soap opera.
Intrigued by both the technical simplicity and potential rewards, I decided to build my own version.
Learning Through Building
What makes this project even more significant for me personally is that before starting this project I had zero experience with Python, web scraping, or databases. I intentionally chose this project as a vehicle to learn these skills with a clear, motivating goal in mind.
This approach of learning by building real projects with concrete outcomes has been my go-to method for acquiring new programming skills. By tackling projects that genuinely interest me, I’ve successfully learned a dozen different programming languages and technologies over the years.
There’s something uniquely effective about having a tangible end goal that keeps you pushing through the inevitable challenges and roadblocks. When you’re excited about what you’re building, debugging becomes a puzzle to solve rather than a chore, and each new concept has immediate practical application.
The contest bot provided perfect scaffolding for learning:
- Python fundamentals through practical application
- API integration via Twitter’s interface
- Database design and management
- Web development through the PHP dashboard
This project-first approach to learning accelerated my skills acquisition far beyond what traditional tutorials or courses could have accomplished in the same timeframe.
Open Source (With Strategic Limitations)
For those interested in creating their own contest bot, I’ve made a version of my code available on GitHub. However, I should note a few important caveats:
This was my first time using Python and my first foray into functional programming, so the code is… let’s say “less than ideal.” It serves as a genuine chronicle of my learning process, complete with all the quirks and inefficiencies of a beginner.
The version I uploaded isn’t actually my most sophisticated iteration. As Twitter began cracking down on bots, I became less concerned about other people starting competing bots and more focused on maintaining my own statistical advantage. Many of the features mentioned in this article as either implemented or roadmap items were actually built into more advanced versions that I never made public.
Consider the GitHub repository a foundation to build upon rather than a polished product. The real value came from the iterations and improvements I made over time as I learned more about Python, Twitter’s API, and bot detection mechanisms.
By keeping my most effective techniques private, I maintained the statistical edge that made this project so successful. After all, the fewer contest bots in operation, the better my chances of winning remained!
How It Works
The functionality is straightforward:
- Search Twitter for contest-related keywords like “retweet to win,” “RT to win,” “contest,” “giveaway”
- Filter results to only include tweets that can be entered on the Twitter platform (request retweets for entry)
- Follow accounts when required as part of the contest rules
- Automatically retweet qualifying tweets
- Track entries and wins for data analysis
- Manage follows/unfollows to stay within Twitter’s limits
- Repeat the process at regular intervals
I also implemented some additional features based on Scotts bot. To prevent getting banned by Twitter, I had to carefully manage rate limits. Twitter restricts how often you can tweet, retweet, and follow/unfollow accounts. Since most contests required following the original poster, I implemented a FIFO (First In, First Out) queue to ensure I was only following the 2,000 most recent contest entries (staying well within Twitter’s following limits).
Reaching The Limits
Working with Tweepy v3.6.0, I quickly discovered how Twitter’s API rate limits became the central challenge for my giveaway bot. These limits were surprisingly restrictive, approximately 300 retweets per day, 1,000 likes per day and 400 follows per day. For searching arguably the most important functio of my bot, I was constrained to just 180 search requests per 15-minute window.
Let’s break down what this meant for my bot’s theoretical maximum capacity: Each search could return up to 180 tweets, letting me scan about ~15,480 tweets daily. However, after filtering for actual giveaways (roughly 5% of tweets contained legitimate contests), I could potentially find about 774 giveaway opportunities daily. Unfortunately, I couldn’t enter them all due to the action limits. The retweet limit of 300 per day became my primary bottleneck, essentially capping my daily entries regardless of how many more contests I discovered.
Given these constraints I optimised what I could, the search API was my most significant constraint that I had control over, like Scott I pivoted to using BeautifulSoup for web scraping Twitter’s interface directly. This approach completely bypassed the search API limits, allowing me to discover substantially more giveaways without hitting the rate limits that restricted my searches. The bot could now crawl Twitter’s web interface continuously, finding thousands of additional contest opportunities that would have been missed using the API alone. This innovation shifted my bottleneck entirely from discovery to action limits (retweets, likes, follows).
The real breakthrough came when I moved away from basic searching functions to a more sophisticated architecture that saved discovered contests into a central SQLITE database. This allowed multiple bot accounts to share the same pool of discovered giveaways, effectively multiplying my entry capacity without increasing the computational overhead of search operations. Rather than each account wastefully duplicating the same search queries, one efficient scraping process could feed contest opportunities to an entire network of bots.
Just using two accounts would theoretically double the number of entries I could perform daily, from 300 to 600 retweets. By the end of the project, I had over half a dozen bots operating at any given time, each capable of the full 300 daily retweets whilst drawing from the same centralised contest database.
Finding Hidden Gems: The Statistical Edge
Unlike Scott, who believes he reached a scale where he was entering virtually every Twitter contest available, my operation was more modest. However, this led to an interesting discovery: my bot was finding giveaways that seemingly no one else was discovering.
This created a significant statistical advantage. When a poorly advertised giveaway had only a handful public entries, and I had multiple bot accounts all running the same search queries, my chances of winning skyrocketed. This scenario played out numerous times. For example one brand, was giving away iTunes gift cards every month. Across my various accounts, I won 5 of their monthly giveaways because so few people even knew they existed.
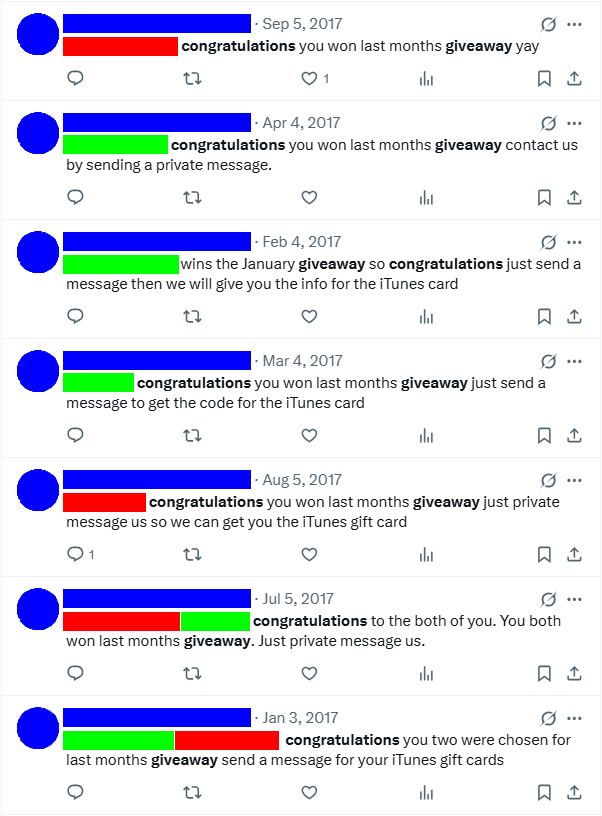
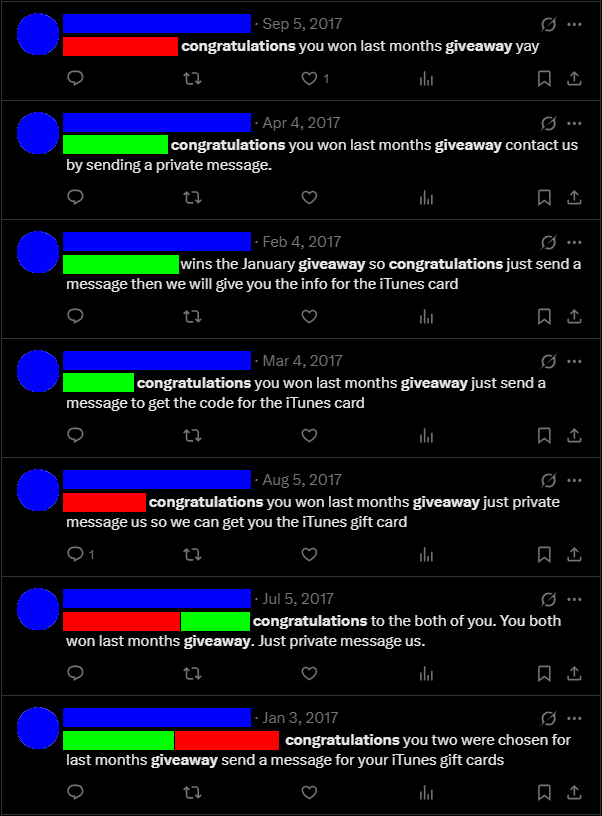 The Itunes giveaway that my bot won consistently (my accounts censored in green other accounts that won in red)
The Itunes giveaway that my bot won consistently (my accounts censored in green other accounts that won in red)
The majority of the items I won were obtained through statistical means, such as entering contests multiple times and discovering giveaways that were not attracting large crowds. I essentially discovered a sweet spot.
That’s not to say I only won the obscure contests. One of my most memorable wins was a copy of the game Rust in a giveaway where my odds of winning were under 2%. This was one of those cases where I would have entered manually if I had known about it, and I was thrilled when my bot managed to beat the odds.
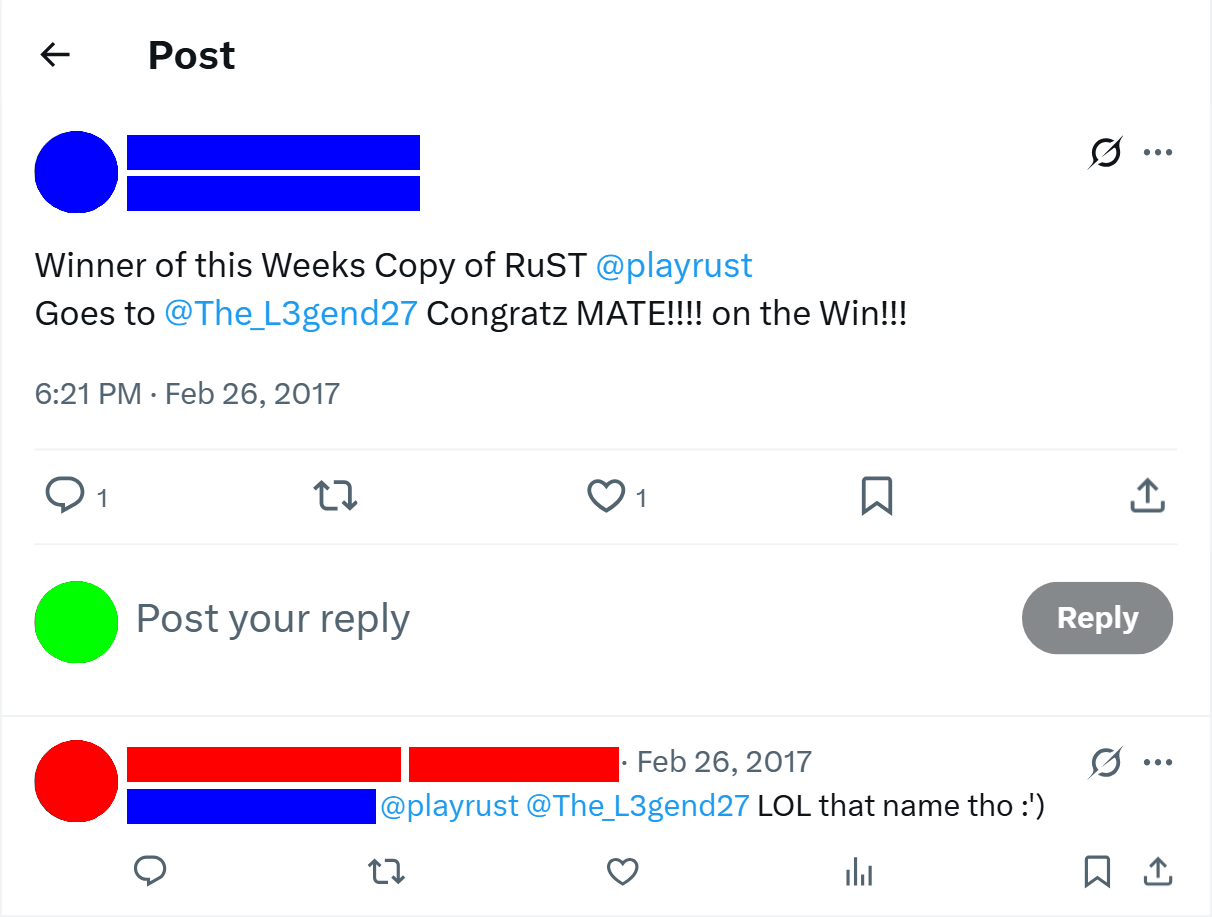
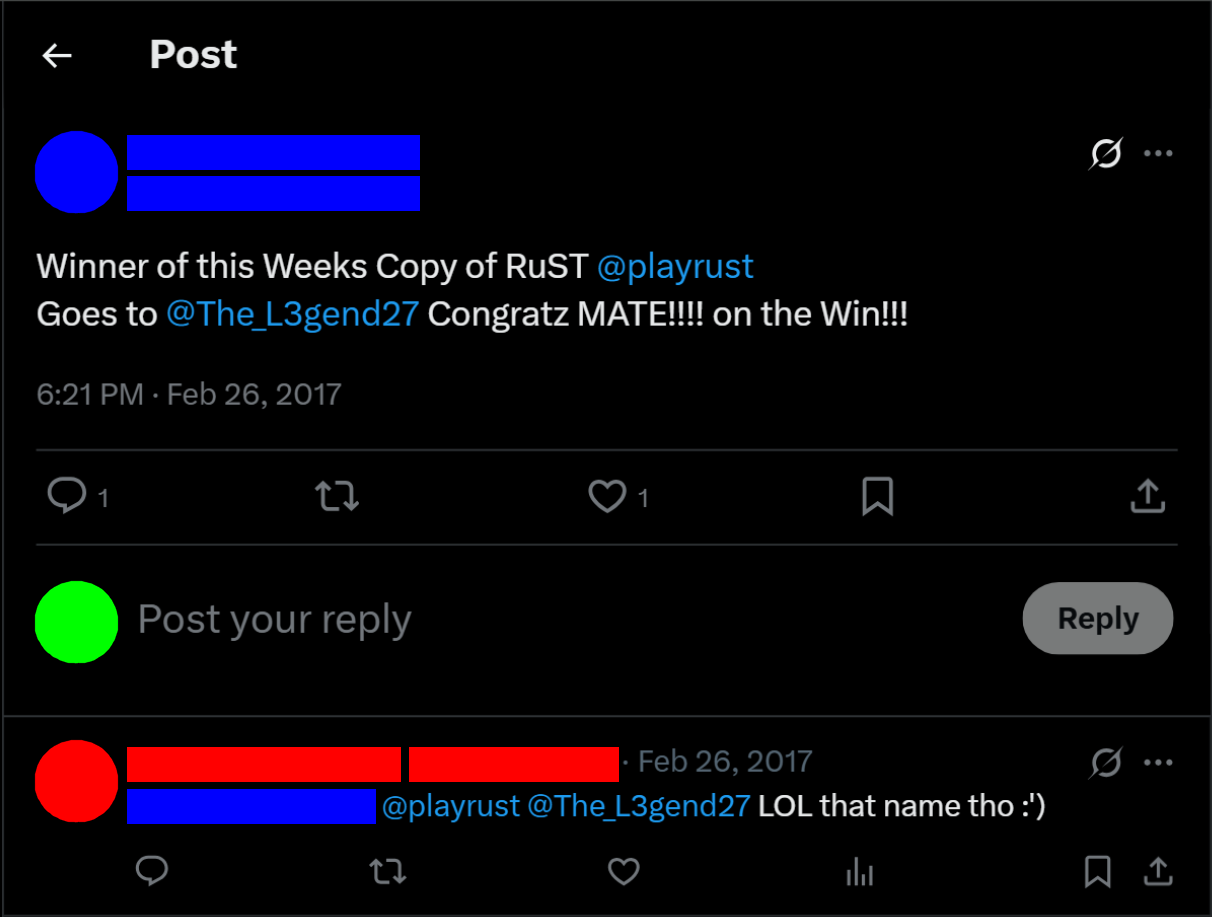 The announcement of the winner of the rust giveaway
The announcement of the winner of the rust giveaway
Blending In
Another way my bot differed, was unlike Scott’s approach of using generic Windows stock photos and minimal profile details (the username “HS” with the description “I’m up all night to get lucky”), I discovered that creating memorable, meme-based personas significantly improved my bot’s perceived legitimacy.
My primary bot account was named “The_L3gend27”, a leet-speak version of the popular mobile gaming meme from 2016 TheLegend27 (the original TheLegend27 username was already taken). This reference to a well-known meme gave my account an immediate cultural context that appeared more authentic than generic or randomly generated names.
I took advantage of one of the most common prizes I won (free graphic design work) to further enhance my profile’s legitimacy. When artists offered banners or profile graphics as giveaway prizes, I would claim them and immediately implement them on my bot accounts. This created a positive feedback loop: winning design giveaways provided me with professional-looking profile elements, which in turn made my accounts look more legitimate for future contests.
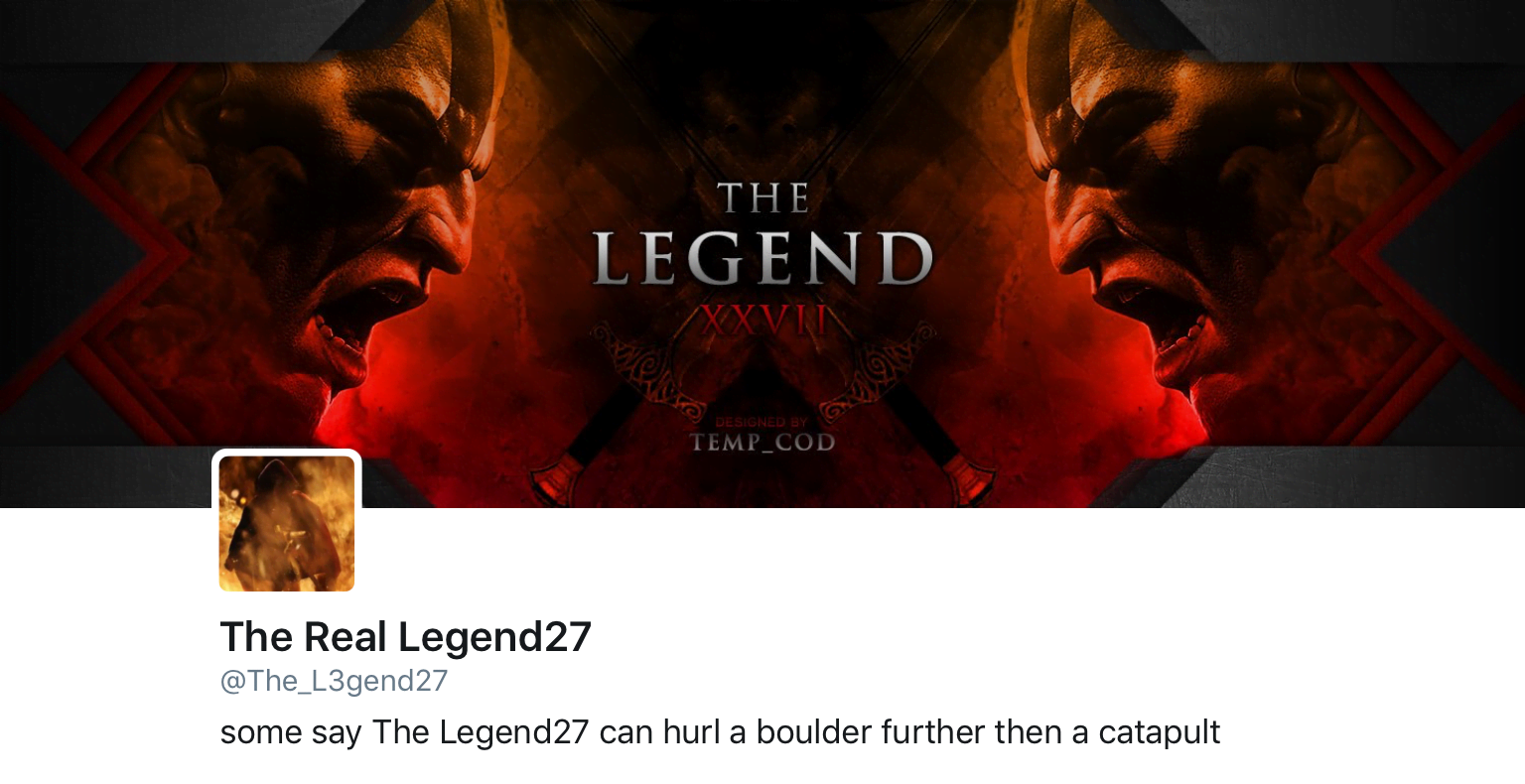 Profile of my primary bot, with banner art won by the bot
Profile of my primary bot, with banner art won by the bot
This strategy paid dividends in unexpected ways. Several contest hosts specifically mentioned recognising my distinctive username when announcing me as a winner. For manually selected giveaways (where hosts weren’t using random selection tools), having a memorable, recognizable name likely increased my chances significantly. The lengthy, distinctive “The_L3gend27” was more likely to catch a host’s eye than forgettable generic usernames.
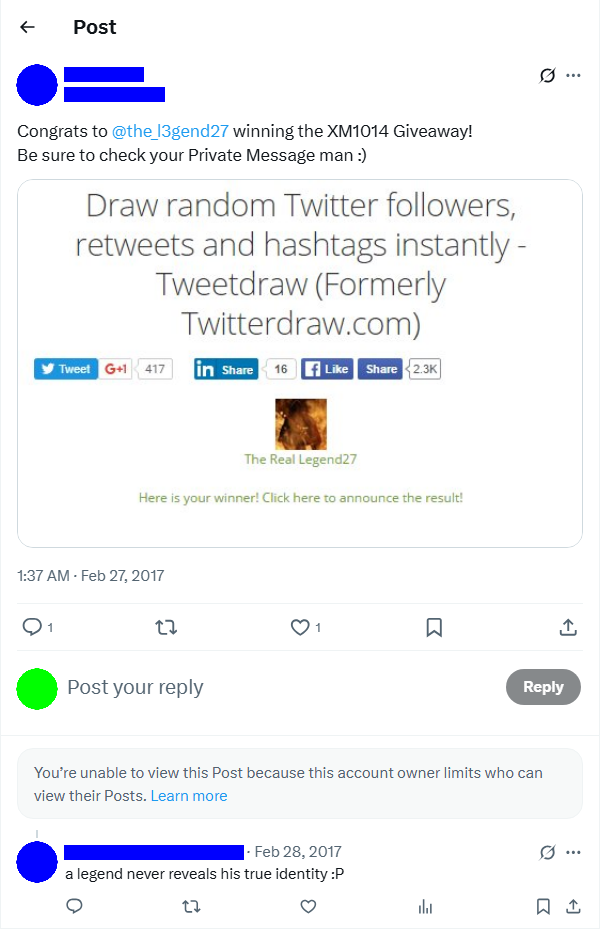
 Host of a giveaway making reference to The Legend27 meme
Host of a giveaway making reference to The Legend27 meme
What Qualified as a Giveaway
One of the most critical challenges in optimising my Twitter contest bot was accurately identifying legitimate giveaways while filtering out false positives. With Twitter’s strict rate limits constraining me to just 300 retweets per day, 1,000 likes per day, and 400 follows per day, every action had to count towards genuine contest opportunities.
I developed a multi-layered filtering system based on pattern recognition and probabilistic scoring. Each discovered tweet received a “giveaway probability score” calculated from multiple weighted signals that determined whether it warranted one of my precious daily actions.
The first layer involved sophisticated keyword filtering that went far beyond simplistic string matching. Many tweets contained phrases like “I just retweeted John Smith’s post I hope I win”, which would trigger basic bots despite not being actual contests. My system required multiple giveaway-specific keywords to appear in logical relationships to each other, such as “retweet AND win” or “RT AND giveaway”, with additional context clues like prize descriptions or entry deadlines.
Most critically, I implemented social action requirements as a key qualifying factor. Since the vast majority of legitimate Twitter giveaways aimed to increase follower counts and engagement metrics, I prioritised contests that explicitly requested following the host account alongside retweets or likes. This single filter dramatically improved my success rate by eliminating noise while focusing on contests where my entry would be properly tracked by the host.
The filtering strategy inevitably meant missing some valid giveaways that didn’t match my strict criteria. However, given Twitter’s fundamental rate limit constraints, attempting to enter every possible contest was mathematically impossible. The platform’s restrictions forced a strategic choice: scatter limited actions across uncertain prospects, or concentrate them on high-probability targets.
Quality over quantity proved to be the optimal approach. Rather than wasting precious daily actions on ambiguous tweets, I focused my constrained resources on contests with the highest legitimacy probability and prize. This targeted strategy maximised both my win rate and the overall value of prizes claimed.
Automating the Collection
Winning dozens of digital prizes weekly created an unexpected problem: claiming all these rewards became a significant time sink. Interacting with contest hosts, providing platform information, or submitting game details manually for each win quickly became unsustainable.
I developed a solution born from necessity: automated prize collection. My bot monitored direct messages for specific patterns and keywords that indicated I had won something, then automatically responded with appropriate information. For digital prizes (which made up most of my winnings), this system was particularly effective. When the bot detected messages containing phrases like “trade link”, it would automatically reply with pre-formatted responses containing my relevant platform information.
Another critical reason for implementing this automation was the time-sensitive nature of many giveaways. Numerous contest hosts would give winners only 30 minutes to respond before redrawing. Living in Australia meant I was often asleep when these messages arrived. A 3 AM notification meant I’d frequently miss out on prizes I’d legitimately won. The automated response system solved this problem entirely, ensuring I could claim prizes regardless of time zone differences.
This automation meant that digital prizes like game keys, in-game items, and account credentials flowed in without any manual intervention, I’d simply check my accounts periodically to find new items waiting.
However, the system wasn’t flawless. Occasionally, users would inadvertently trigger the automated responses during normal conversations, leading to some genuinely confusing moments. Someone might casually mention a “trade link” or use other trigger phrases in context, only to receive an unexpected automated response containing my Steam trade link. These incidents were typically brushed off after a confused “huh?” response, and most people seemed to either ignore the oddity. Fortunately, I never encountered anyone who discovered the trigger phrases and deliberately exploited them repeatedly, a very real risk that could have made the bot’s automated nature embarrassingly obvious to the broader Twitter community.
Combating the Bot Spotters
Another fascinating discovery during this project was the existence of “bot spotters”. These are accounts specifically designed to catch and expose contest bots like mine. These accounts, often named something like “bot_spotter” or using variations with leet speak (b0t_sp0tt3r), would cleverly tweet contest-like phrases containing all the keywords our bots look for.
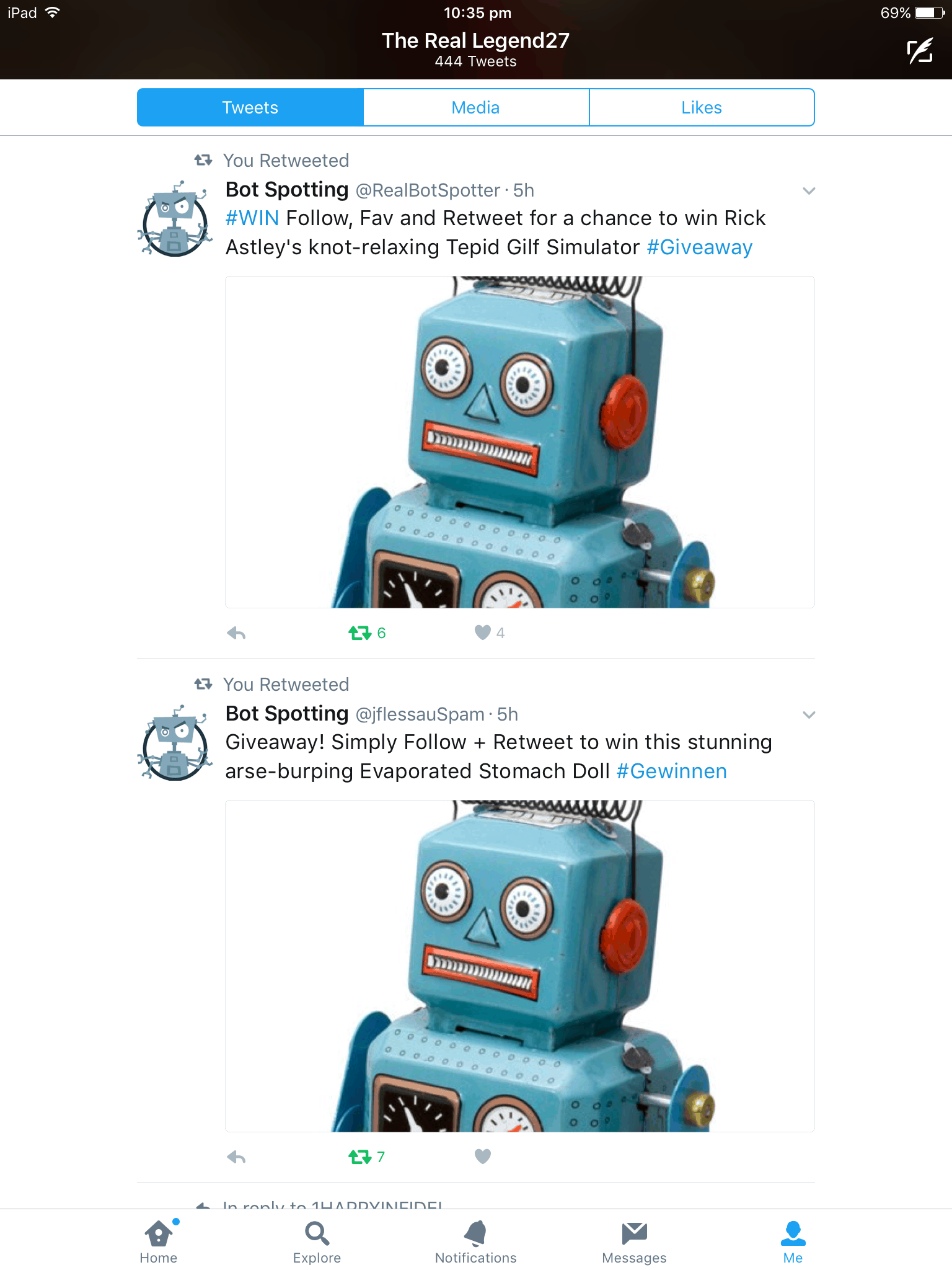 An early itteration of my bot falling for bot spotting accounts
An early itteration of my bot falling for bot spotting accounts
To counteract this, I implemented several protective measures:
I developed a multi-pronged detection system that monitored accounts for suspicious patterns. The first layer involved scanning usernames for variations of “bot,” “spotter,” “sp0tter,” and similar terms that these accounts typically used. However, username filtering alone wasn’t sufficient, as some bot spotters used completely innocuous names.
The second layer tracked giveaway frequency patterns. My system maintained a database of how many “contests” each account had posted over various time periods. Any account exceeding predetermined thresholds such as posting more than five giveaways in a single day or twenty in a week, would trigger automatic blocking. Legitimate brands and influencers rarely posted contests with such frequency, making this an effective filter.
When these thresholds were breached, the offending accounts entered a quarantine system. Rather than permanently blocking potentially legitimate accounts, suspicious users remained in quarantine until I could manually review and verify them. This prevented false positives while maintaining protection against bot spotters who might attempt to evade detection by changing usernames or tactics.
This “arms race” between bots and bot spotters added an unexpected but fascinating dimension to the project!
The Dark Side of Twitter Contests
Running this bot revealed a troubling reality: a large portion of the contests I “won” had sinister surroundings.
The most common scam I encountered involved “winners” being told they needed to pay small “delivery fees” to claim extravagant prizes like gaming consoles or smartphones. These scammers operated on a simple principle: the excitement of winning something valuable would cloud the winner’s judgment enough to overlook the red flag of paying a fee.
These delivery fee scams were just the tip of the iceberg. Other common patterns included:
- Contest hosts who never actually delivered prizes or responded to winners once they made contact
- Accounts running perpetual contests to artificially inflate follower counts with no intention of ever giving anything away
- Sophisticated phishing schemes disguised as contest verification, designed primarily to harvest personal information, passwords, or credit card details
- Contests requiring excessive personal details for entry that were likely being compiled into marketing databases
- “Follow loops” where multiple accounts would cross-promote each other’s fake giveaways to rapidly build their follower base
Perhaps most concerning was the significant number of giveaways offering stolen goods as prizes. The most prevalent were stolen accounts for premium services like Netflix, Spotify, Minecraft, Steam, and other gaming platforms. These contests were essentially fencing operations disguised as generous giveaways.
Becoming a Tweepy Expert and Giving Back
After wrestling with the Tweepy library for many months to build and refine this project, I developed a deep understanding of Twitter’s API and the nuances of Tweepy. I encountered numerous challenges that had no clear solutions online, forcing me to dig deep into the documentation and experiment extensively.
When searching for solutions to my own development challenges, I frequently encountered the same unanswered questions on Stack Overflow that had been plaguing other developers for months or even years. Remembering my own frustration when facing these roadblocks with no available solutions, I decided to become the kind of Stack Overflow contributor I wished I’d found during my development process.
I focused particularly on Tweepy-related questions that mirrored the exact challenges I had wrestled with during development. These ranged from basic searching and filtering techniques to more complex problems around cursor pagination and error handling issues that had little to no clear documentation or working examples available online. My Stack Overflow contributions became a way of documenting the solutions I wished had existed when I was struggling through the same problems months earlier.
Initially, I only responded to a few new questions, hoping those users would still be interested in a solution. The response was overwhelmingly positive, and I found myself enjoying the process of helping others overcome the same hurdles I had faced. This unexpected side effect of the project led to me climbing into the top percentage of Stack Overflow users for a period, which was a rewarding achievement in itself.
The Results
When I first launched my Twitter contest bot in January 2017, I was meticulous about tracking every single win, no matter how small. I quickly discovered that maintaining this list became a job in itself. After just over a month, I abandoned the formal tracking as the volume of wins (particularly low-value digital items) made it impractical to document everything.
My One-Month Haul
During that first month of careful record-keeping (January-February 2017), my bot managed to win 75 prizes in just over 30 days. That averages to about 2.5 wins per day - not quite as prolific as Hunter Scott’s 4 per day, but surprisingly effective considering how primitive my system was at this stage.
It’s important to note that during this initial period, my bot was extremely inefficient. It was still struggling with filtering out non-contest tweets and was entirely limited to Twitter’s cursor search functions, which would return a maximum of 180 tweets per query. Even worse, many of these returned tweets were duplicates, severely reducing my theoretical maximum discovery rate. The filtering algorithm was also quite basic at this point, frequently wasting precious retweet actions on false positives that weren’t actual contests.
Looking at the categories of items won during this tracked period (the complete list of wins provides the full details):
- Digital accounts/subscriptions: 20 items (26.7%) - including Netflix, Spotify, Minecraft, and Crunchyroll accounts
- In-game items/currency: 19 items (25.3%) - CS:GO skins, Pokémon codes, game server ranks
- Digital services: 12 items (16%) - banners, GFX designs, 3D intros
- Cash/gift cards: 5 items (6.7%) - ranging from $0.03 PayPal to $15 iTunes cards
- Physical items: 19 items (25.3%) - including gaming hardware, clothes, collectables, and kitchenwear
Unlike Scott, who tracked every win over his 9-month project and published a complete list of winnings, my tracking dropped off precisely because the volume became unmanageable alongside my other responsibilities. In hindsight, this was a missed opportunity for more comprehensive data analysis.
I would also go through the DMs to see what I won, but unfortunately, during Twitter’s crackdown on bots, many accounts were nuked, including my bot accounts and even those of my adversaries (those pesky bot spotters). That’s made finding evidence and media for this post particularly difficult (hence all the light mode screenshots - I’m sorry). However, whilst the accounts have been suspended, if you know where to look you can still find other people’s announcements of me winning their competitions using Twitter advanced searches like this one.
The Ethical Accounting
It’s worth noting that many of my “wins” were ethically questionable in retrospect. The digital accounts that comprised 30% of overall winnings were clearly compromised or stolen goods being redistributed through these contests. While I didn’t utilise these prizes, they represent a significant portion of the “value” generated by the bot.
Discovery and Exposure
In retrospect, it should have been extremely obvious that my account was a bot. My accounts like “The_L3gend27” were doing nothing but entering giveaways 24/7 with no apparent sleep schedule, posting no original content, and never engaging in normal social interactions. Despite my attempts to create a memorable persona, the behavioral patterns were a dead giveaway to anyone paying attention.
I did get called out a few times, mostly via direct messages, but occasionally publicly. These public call-outs were particularly damaging because they would cause me to lose giveaways I would have otherwise won. Contest hosts who saw comments like “this is obviously a bot account” would often disqualify me even after initially announcing me as a winner.
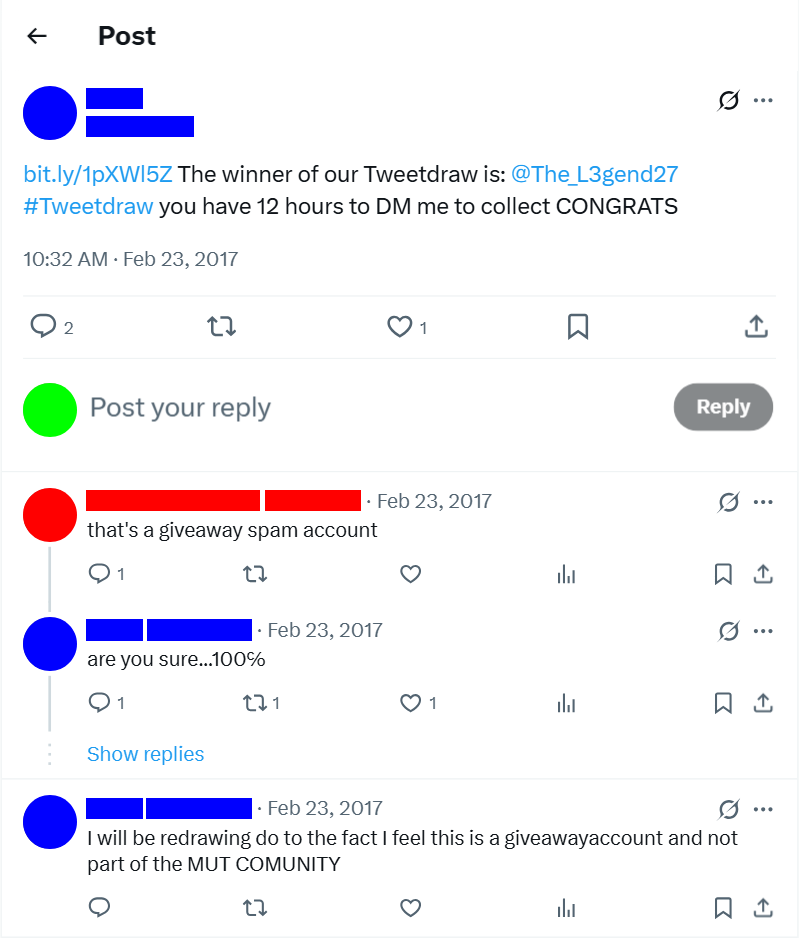
 Eaxmple of public accusations of bot behavior that cost me several prizes
Eaxmple of public accusations of bot behavior that cost me several prizes
Interestingly, I also received messages from users who had figured out a clever strategy: they used my account as a giveaway discovery service. Rather than building their own filtering systems, they would simply monitor my retweets to find active contests. This was actually brilliant - they shifted all the computational overhead of finding and filtering giveaways onto my bot while simultaneously degrading my odds of winning by increasing competition. They got a curated feed of legitimate giveaways without any of the development work, while I unknowingly provided them with a competitive advantage against my own operation.
Conclusion
Scott’s DEF CON talk demonstrated how a simple script could achieve impressive results through automation at scale. My implementation confirmed that the approach still worked years later, though Twitter’s landscape continued to evolve.
The project perfectly illustrates how programming allows us to automate repetitive tasks, apply statistical advantages at scale, and occasionally win free stuff along the way. It also offers a fascinating glimpse into the ecosystem of online contests.
Beyond the prizes, this project yielded unexpected benefits: it served as an effective vehicle for learning Python, web scraping, and database management from scratch. It reinforced my belief that project-based learning with clear goals is the fastest way to acquire new programming skills. The knowledge gained allowed me to contribute to the developer community and help others facing similar challenges.
If you’re looking to learn a new programming language or technology, I strongly recommend finding a project that genuinely interests you and diving in. The motivation of building something real will carry you through the learning curve far more effectively than abstract tutorials ever could.
Note: If you plan to create your own contest bot, be sure to review Twitter’s current Developer Policy and Terms of Service to ensure compliance.
PS If you also ran or are running a Twitter giveaway bot, I’d love to hear about your experiences. Use the contact link to share your story!